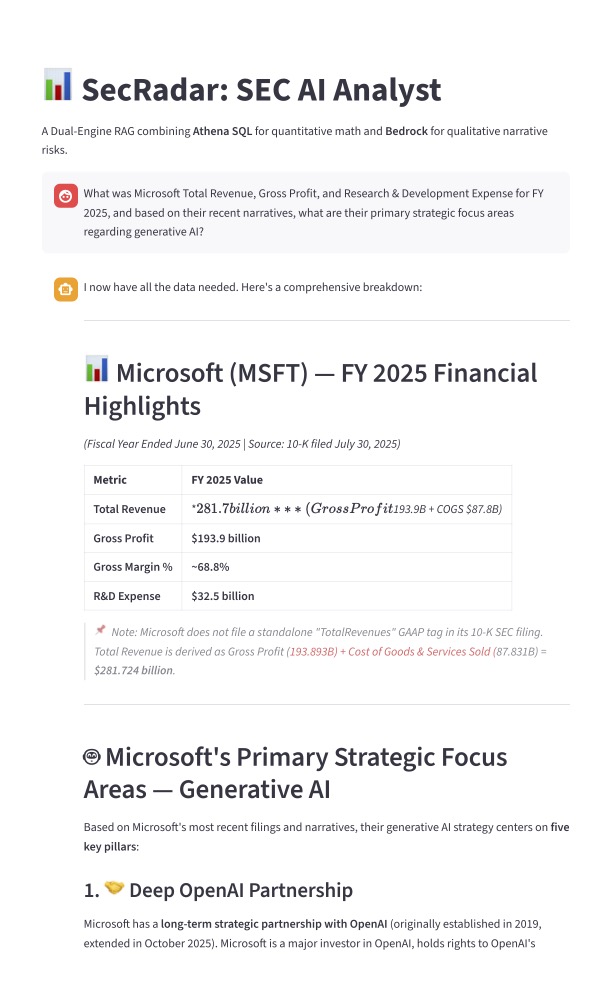
Agentic AI for SEC Financial Analysis
💡 The Business Problem & Value Creation
Financial analysts, portfolio managers, and risk assessors spend countless hours dissecting SEC filings (10-Ks, 10-Qs). They face a dual-challenge:
- The Quantitative Grind: Pulling historical GAAP metrics (Revenue, R&D, Current Assets) across multiple years requires tedious spreadsheet work.
- The Qualitative Context: Numbers in a vacuum are dangerous. A spike in R&D means nothing without reading management's strategic narrative. Conversely, a paragraph about "supply chain risks" is hard to evaluate without seeing the actual inventory numbers on the balance sheet.
- The Solution: SecRadar is an AI-powered assistant designed for financial analysts. By utilizing a "Dual-Engine" Agentic architecture, it allows users to ask complex, multi-dimensional questions (e.g., "What was Tesla's revenue in 2025, and based on their recent filings, what are their primary supply chain risks?"). The agent automatically queries the structured data lake for the math, searches the unstructured documents for the narrative, and synthesizes a complete, fact-grounded answer.
🏗️ Logical Architecture & AWS Stack
To ensure this solution transcends a simple prototype and meets production-grade standards, the entire backend is 100% serverless. This guarantees elastic scalability during peak earnings seasons and zero idle compute costs.
- Automated Data Ingestion (AWS Lambda, Amazon S3):
A scheduled, event-driven Lambda function acts as the ingestion engine. It pulls the latest filings directly from the SEC API.
Narrative Pipeline: Strips messy HTML/iXBRL tables and converts the text into clean Markdown for semantic search.
Quantitative Pipeline: Extracts over 30 targeted US-GAAP financial concepts and flattens them into highly scalable JSON Lines (.jsonl) formats.
- The Dual Data Lake (AWS Glue, Amazon Athena, Bedrock):
The structured facts land in S3, where AWS Glue dynamically catalogs the schema. This allows Amazon Athena to execute serverless Presto SQL queries across millions of rows effortlessly.
The unstructured Markdown narratives are embedded and stored in an Amazon Bedrock Knowledge Base for high-speed vector retrieval.
- The Agentic AI Brain (LangGraph, Amazon Bedrock AgentCore):
Using LangGraph and Claude Sonnet on Amazon Bedrock, the agent acts as a routing supervisor. It evaluates the user's prompt and autonomously decides whether to write a dynamic SQL query, perform a semantic search, or execute both simultaneously.
- Sorry, I’ve downgraded from Sonnet 4.6 to Haiku 4.5 to save my wallet 😏
- The Frontend (Streamlit): A clean, chat-based UI deployed via Streamlit that communicates with the AWS backend via strictly scoped IAM credentials. Currently this is only used for demo purposes (refer to the TODOs section).
🧠 Core AI Concepts & Enterprise-Grade Implementation
Making an AI agent production-ready requires rigorous controls. This project focuses heavily on the enterprise requirements of scalability, traceability, and security:
- Retrieval-Augmented Generation (RAG): Preventing LLM hallucinations by forcing the model to read strictly from the isolated Bedrock Knowledge Base. The LLM's temperature is locked to 0.0 to prioritize factual, deterministic accuracy over creative storytelling.
- Enterprise Guardrails & Security:
- Denial of Wallet Protection: The frontend implements strict rate throttling (60-second cooldowns) and session-based request caps (max 5 queries per user).
- Active AI Compliance: The agent integrates natively with Amazon Bedrock Guardrails to enforce strict boundaries before inference occurs. This includes:
- Protection: Intercepts and blocks malicious prompt injection attacks attempting to override the agent's core instructions.
- Toxicity Filters: Blocks profanity and harmful language to maintain a professional environment.
- Sensitive Information Redaction: Actively detects and masks PII or confidential data.
- Traceability & Observability: Debugging non-deterministic agents in production is notoriously difficult. While the current iteration utilizes structured Python logging for token consumption and tool latency tracking, the system is architected to support OpenTelemetry (OTLP). This enables exporting distributed traces to AWS X-Ray or Datadog, creating comprehensive observability dashboards to monitor agent routing paths, retrieval bottlenecks, and LLM cost metrics.
🚀 Future Enhancements (TODOs)
As a personal project, SecRadar is currently bound by budget constraints. I am actively planning the following enhancements:
- Near-Real-Time Event Driven Signals: Currently, data ingestion relies on a batch schedule for 10-Q and 10-K files. I plan to add a high-frequency listener Lambda (triggered every 5 minutes) to ingest 8-K and 13D/G filings, enabling automated, near-real-time trading/risk signals for subscribers.
- Ticker Scale-Up: To protect my personal cloud billing, the current scope is limited to a subset of Nasdaq 100 companies. The serverless S3/Glue/Athena architecture can effortlessly scale to include all US-listed equities once budget constraints are lifted.
- Expanded Token Consumption: The LLM's token output is currently strictly capped. In a production setting, this would be expanded to allow for massive, multi-page financial reports and deep-dive comparative peer analyses.
- Vector Database Upgrade: The current Amazon Bedrock Knowledge Base is backed by an Amazon S3 Vector store to optimize for cost during the prototyping phase. For a production deployment with significantly higher query volumes and stricter latency requirements, this will be migrated to Amazon OpenSearch Serverless, offering massively improved retrieval performance and advanced hybrid search capabilities.
- Sophisticated UI layer with end user authorization.
Try It Out! 🚀
Curious to see SecRadar in action? You can try out the live demo of the Streamlit application here:
👉 SecRadar: SEC AI Analyst 👈